
[데이터 전처리] 결측치 (Missing Value)
이 글은 결측치의 개념, 종류, 그리고 결측치 처리 방법에 관한 기록입니다.
결측치 (Missing Value) 개념
- 결측치 : 누락된 데이터 : Null, NaN, NA
- 파이썬 :
None,np.nan,pd.NaT - 판다스 :
None,NaN
결측치 종류
결측치에는 크게 완전 무작위 결측 (MCAR), 무작위 결측 (MAR), 비무작위 결측 (MNAR) 세가지 유형이 존재합니다. 이에 대해 자세하게 살펴보겠습니다.
- 완전 무작위 결측 (Missing Completely at Random ; MCAR)
- 어떤 변수의 결측치가 무작위로 발생한 경우 (다른 변수와 관련 X)
- 무작위 결측 (Missing at Random ; MAR)
- 어떤 변수의 결측치의 발생 여부가 다른 변수와 관련이 있는 경우
- 값의 상관관계 알 수 X
- 비무작위 결측 (Missing Not at Random ; MNAR)
- 어떤 변수의 결측치의 값이 다른 변수와 관련이 있는 경우
- 값의 상관관계 O
결측치 처리 방법 개요
결측치를 처리하는 데에는 다양한 방법이 존재합니다.
결측치 비율에 따른 결측치 처리 방법 선택
| 결측치 비율 | 결측치 처리 방법 |
|---|---|
| 10% 미만 | 제거 또는 대체 |
| 10% 이상 20% 미만 | 모델 기반 처리 |
| 20% 이상 | 모델 기반 처리 |
1. Deletion
결측치가 있는 행이나 열을 제거하는 방법입니다. 완전한 데이터에 대해서만 분석을 진행한다고 볼 수 있습니다. 결측치가 포함된 행이나 열이 많을 경우 데이터 손실이 크다는 단점이 있습니다.
2. Heuristic Imputation
분석가가 보편적인 사실(상식) 혹은 도메인 지식에 기반하여 임의로 결측치를 대체하는 방법입니다.
3. Mean//Median/Mode Imputation
결측치를 평균/중앙값/최빈값 등의 대표값으로 대체하는 방법입니다. 이때 대표값은 전체의 대표값일 수도, 특정 집단의 대표값일 수도 있습니다.
4. Prediction Model
모델을 통해 예측한 값으로 결측치를 대체하는 방법입니다. 이때 사용되는 모델로는 KNN 등이 있습니다.
결측치 처리 방법 with Python Code
아래의 코드 사용된 데이터셋은 이곳에서 다운로드 받을 수 있습니다.
# 패키지 불러오기
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
# 경고 무시하기
import warnings
warnings.filterwarnings(action='ignore')
# 데이터 불러오기
df = pd.read_csv('../data/titanic/train.csv', index_col=0)
df
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 887 | 0 | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.0000 | NaN | S |
| 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S |
| 889 | 0 | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | S |
| 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | C |
| 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q |
891 rows × 11 columns
# 데이터 확인하기
df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 891 entries, 1 to 891
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Survived 891 non-null int64
1 Pclass 891 non-null int64
2 Name 891 non-null object
3 Sex 891 non-null object
4 Age 714 non-null float64
5 SibSp 891 non-null int64
6 Parch 891 non-null int64
7 Ticket 891 non-null object
8 Fare 891 non-null float64
9 Cabin 204 non-null object
10 Embarked 889 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 83.5+ KB
NA 확인하기
파이썬에서 결측치를 확인하는 데에는 크게 df.isnull()과 df.notnull()이 사용됩니다.
먼저 df.isnull()을 활용하여 결측치를 확인해보겠습니다. df.isnull()은 해당 셀의 데이터가 결측치이면 Ture, 결측치가 아니면 False를 값으로 갖는 데이터프레임을 보여줍니다.
df.isnull()
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||
| 1 | False | False | False | False | False | False | False | False | False | True | False |
| 2 | False | False | False | False | False | False | False | False | False | False | False |
| 3 | False | False | False | False | False | False | False | False | False | True | False |
| 4 | False | False | False | False | False | False | False | False | False | False | False |
| 5 | False | False | False | False | False | False | False | False | False | True | False |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 887 | False | False | False | False | False | False | False | False | False | True | False |
| 888 | False | False | False | False | False | False | False | False | False | False | False |
| 889 | False | False | False | False | True | False | False | False | False | True | False |
| 890 | False | False | False | False | False | False | False | False | False | False | False |
| 891 | False | False | False | False | False | False | False | False | False | True | False |
891 rows × 11 columns
df.isnull().sum()은 각 컬럼 별로 결측치가 몇 개인지를 보여줍니다.
# 결측치 개수
df.isnull().sum()
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
각 컬럼 별로 결측치가 얼마만큼의 비율을 차지하고 있는지도 볼 수 있습니다.
# 결측치 proportion
(df.isnull().sum()/len(df)).round(2)
Survived 0.00
Pclass 0.00
Name 0.00
Sex 0.00
Age 0.20
SibSp 0.00
Parch 0.00
Ticket 0.00
Fare 0.00
Cabin 0.77
Embarked 0.00
dtype: float64
각 컬럼 별로 결측치가 얼마만큼의 퍼센트를 차지하고 있는지도 볼 수 있습니다.
# 결측치 percentage
(df.isnull().sum()/len(df)*100).sort_values(ascending=False)
Cabin 77.104377
Age 19.865320
Embarked 0.224467
Fare 0.000000
Ticket 0.000000
Parch 0.000000
SibSp 0.000000
Sex 0.000000
Name 0.000000
Pclass 0.000000
Survived 0.000000
dtype: float64
다음으로 df.notnull()을 활용하여 결측치를 확인해보겠습니다. df.notnull()은 해당 셀의 데이터가 결측치가 아니면 Ture, 결측치이면 False를 값으로 갖는 데이터프레임을 보여줍니다.
df.notnull()
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||
| 1 | True | True | True | True | True | True | True | True | True | False | True |
| 2 | True | True | True | True | True | True | True | True | True | True | True |
| 3 | True | True | True | True | True | True | True | True | True | False | True |
| 4 | True | True | True | True | True | True | True | True | True | True | True |
| 5 | True | True | True | True | True | True | True | True | True | False | True |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 887 | True | True | True | True | True | True | True | True | True | False | True |
| 888 | True | True | True | True | True | True | True | True | True | True | True |
| 889 | True | True | True | True | False | True | True | True | True | False | True |
| 890 | True | True | True | True | True | True | True | True | True | True | True |
| 891 | True | True | True | True | True | True | True | True | True | False | True |
891 rows × 11 columns
아래 코드를 통해 결측치를 제외한 데이터프레임을 확인할 수 있습니다.
df[df['Age'].notnull()]
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 0 | 3 | Rice, Mrs. William (Margaret Norton) | female | 39.0 | 0 | 5 | 382652 | 29.1250 | NaN | Q |
| 887 | 0 | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.0000 | NaN | S |
| 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S |
| 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | C |
| 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q |
714 rows × 11 columns
df.notnull().sum()은 각 컬럼 별로 결측치 아닌 데이터가 몇 개인지를 보여줍니다.
# 결측치가 아닌 데이터 개수
df.notnull().sum()
Survived 891
Pclass 891
Name 891
Sex 891
Age 714
SibSp 891
Parch 891
Ticket 891
Fare 891
Cabin 204
Embarked 889
dtype: int64
NA Imputation - Deletion (수치형 변수 O / 범주형 변수 O)
Deletion은 결측치를 제거하는 방법입니다. 주로 결측치가 매우 적을 때 사용합니다. MCAR을 가정합니다. 쉽고, 원래의 분포를 보존한다는 장점을 갖습니다. 한편 데이터 손실이 발생하여 의미있는 데이터를 잃을 수도 있다는 단점을 갖습니다. 파이썬에서는 df.dropna(axis=0)를 통해 결측치가 있는 행을 제거할 수 있습니다.
# 결측치가 있는 행 제거 : df.dropna(axis=0)
df_droprows = df.dropna(axis=0)
# 확인
print(df_droprows.shape)
(183, 11)
df.dropna(axis=1)를 통해 결측치가 있는 열을 제거할 수 있습니다.
# 결측치가 있는 열 제거 : df.dropna(axis=1)
df_dropcols = df.dropna(axis=1)
# 확인
print(df_dropcols.shape)
(891, 8)
NA Imputation - Mean/Median imputation (수치형 변수 O / 범주형 변수 O)
Mean/Median imputation은 결측치를 해당 변수의 평균/중앙값으로 대체하는 방법을 말합니다. 일반적으로 과적합(overfitting)을 피하기 위해 train셋에서 결측치를 대체할 값을 구한 후 이를 train셋과 test셋에 동일하게 적용합니다. MCAR을 가정합니다. 쉽고, 빠르다는 장점을 갖습니다. 한편 원래의 분산을 변형시킬 수 있고, 원래의 공분산을 변형시킬 수 있다(즉 다른 변수와의 관계가 변형될 수 있다)는 단점을 갖습니다. 파이썬에서는 df.fillna()를 통해 결측치를 평균, 중앙값 등의 대표값으로 대체할 수 있습니다.
X = df.drop('Survived', axis=1)
y = df['Survived']
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.3,
random_state=0)
print('training predictors size:', X_train.shape)
print('training response size:', y_train.shape)
print('test predictors size:', X_test.shape)
print('test response size:', y_test.shape)
training predictors size: (623, 10)
training response size: (623,)
test predictors size: (268, 10)
test response size: (268,)
# train셋에서의 mean, medain 확인
print(X_train['Age'].mean())
print(X_train['Age'].median())
29.915338645418327
29.0
# NA imputation
df['Age_mean'] = df['Age'].fillna(X_train['Age'].mean())
df['Age_median'] = df['Age'].fillna(X_train['Age'].median())
# 확인
df[['Age', 'Age_mean', 'Age_median']].isnull().sum()
Age 177
Age_mean 0
Age_median 0
dtype: int64
앞서 언급했듯이, Mean/Median imputation의 경우 원래의 분산을 변형시킬 수 있다는 단점이 존재합니다. 이를 코드를 통해 확인해보겠습니다.
# 분산 계산
print('Original Variance: ', df['Age'].std())
print('Variance after mean imputation: ', df['Age_mean'].std())
print('Variance after median imputation: ', df['Age_median'].std())
Original Variance: 14.526497332334042
Variance after mean imputation: 13.002301745416018
Variance after median imputation: 13.005010341761803
실제로 원래의 분산과 Mean/Median imputation 후의 분산이 다른 것을 볼 수 있습니다.
# 분포 시각화
fig, ax = plt.subplots(figsize=(10,6))
df['Age'].plot(kind='kde', ax=ax, color='blue')
df['Age_mean'].plot(kind='kde', ax=ax, color='red')
df['Age_median'].plot(kind='kde', ax=ax, color='green')
lines, labels = ax.get_legend_handles_labels()
ax.legend(lines, labels, loc='best')
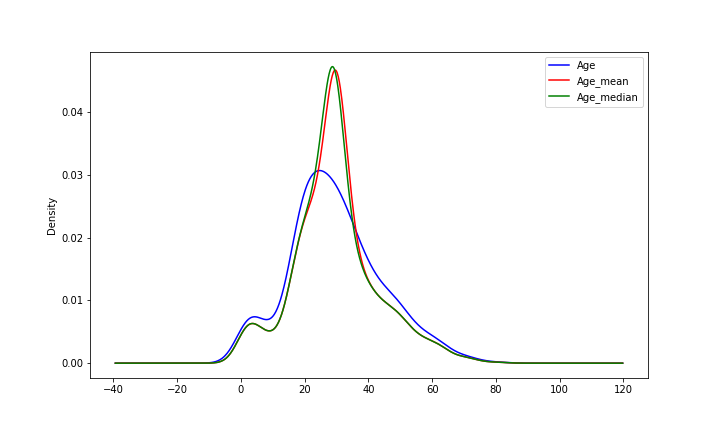
실제로 원래의 분포와 Mean/Median imputation 후의 분포가 다른 것도 볼 수 있습니다.
NA Imputation - Random sample imputation (수치형 변수 O / 범주형 변수 X)
Random sample imputation은 결측치를 해당 변수의 랜덤한 값으로 대체하는 방법을 말합니다. Mean/Median imputation과 비슷하지만, 원래의 분포를 유지하고자 한다는 점에서 차이를 보입니다. MCAR을 가정합니다. 쉽고, 원래의 분포를 보존하고, 원래의 분산을 보존한다는 장점을 갖습니다. randomness가 존재하고, risky하다는 단점을 갖습니다. 파이썬에서는 df.sample(n=결측치 개수)을 통해 결측치를 랜덤한 값으로 대체할 수 있습니다.
df['Age_random'] = df['Age']
# random sampling
temp = (df['Age'].dropna().sample(df['Age'].isnull().sum()))
temp.index = df[lambda x: x['Age'].isnull()].index # index 부여
# NA imputation
df.loc[df['Age'].isnull(), 'Age_random'] = temp
# 확인
df[['Age', 'Age_random']].isnull().sum()
Age 177
Age_random 714
dtype: int64
앞서 언급했듯이, Mean/Median imputation과 달리 Random sample imputation의 경우 원래의 분산 및 분포를 보존한다는 장점이 존재합니다. 이를 시각화를 통해 확인해보겠습니다.
# 분포 시각화
fig, ax = plt.subplots(figsize=(10,6))
df['Age'].plot(kind='kde', ax=ax, color='blue')
df['Age_random'].plot(kind='kde', ax=ax, color='brown')
lines, labels = ax.get_legend_handles_labels()
ax.legend(lines, labels, loc='best')
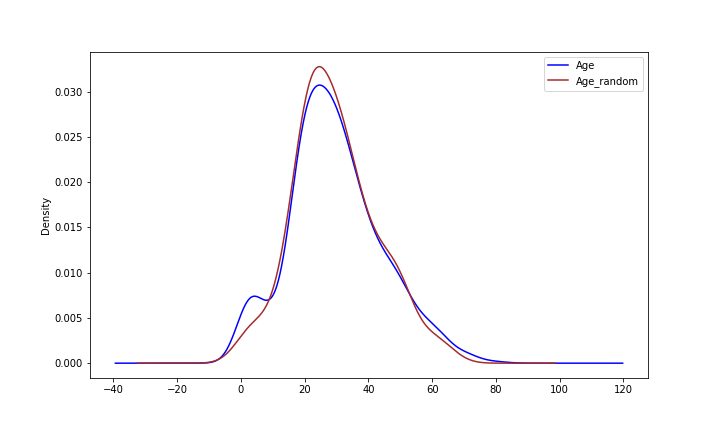
실제로 원래의 분포와 Random sample imputation 후의 분포가 비슷한 것을 볼 수 있습니다.
NA Imputation - Frequent category imputation (수치형 변수 X / 범주형 변수 O)
Frequent category imputation은 결측치를 해당 변수에서 가장 빈도 수가 높은 범주로 대체하는 방법을 말합니다. MCAR을 가정합니다. 쉽다는 장점을 갖습니다. 원래의 분포를 변형시킬 수 있고, 결측치가 많을 경우 빈도 수가 높은 범주가 over-representation 될 수 있다는 단점을 갖습니다. 파이썬에서는 df.fillna()를 통해 결측치를 가장 빈도 수가 높은 범주로 대체할 수 있습니다.
# 범주 별 빈도 수 확인
df['Embarked'].value_counts()
S 644
C 168
Q 77
Name: Embarked, dtype: int64
# NA imputation
df['Embarked_filled'] = df['Embarked'].fillna(df['Embarked'].value_counts(ascending=False).index[0])
# 확인
df[['Embarked', 'Embarked_filled']].isnull().sum()
Embarked 2
Embarked_filled 0
dtype: int64
NA Imputation - Adding a Variable to capture NA (수치형 변수 O / 범주형 변수 O)
결측치일 때에는 1을 결측치가 아닐 때에는 0을 값으로 갖는 변수(variable)를 새롭게 생성할 수 있습니다. MCAR이 아님을 가정합니다. 쉽고, missingness를 유지할 수 있다는 장점을 갖습니다. 차원이 증가한다는 단점을 갖습니다. 파이썬에서는 np.where(df.isnull(), 1, 0)을 통해 결측치일 때는 1을 결측치가 아닐 때에는 0을 값으로 갖는 변수를 새롭게 생성할 수 있습니다.
먼저 수치형 변수에 대해 NA imputation을 진행해보겠습니다.
# NA imputation
df['Age_isnull'] = np.where(df['Age'].isnull(), 1, 0) # null이면 1, 아니면 0
# 확인
df[['Age','Age_isnull']].isnull().sum()
Age 177
Age_isnull 0
dtype: int64
다음으로 범주형 변수에 대해 NA imputation을 진행해보겠습니다.
# NA imputation
df['Embarked_isnull'] = np.where(df['Embarked'].isnull(), 1, 0) # null이면 1, 아니면 0
# 확인
df[['Embarked', 'Embarked_isnull']].isnull().sum()
Embarked 2
Embarked_isnull 0
dtype: int64
NA Imputation - Adding a Category to capture NA (수치형 변수 X / 범주형 변수 O)
결측치일 때에 속하는 범주(category)를 새롭게 생성할 수 있습니다. 주로 결측치가 많을 때 사용합니다. 쉽고, missingness를 유지할 수 있다는 장점을 갖습니다. 한편 결측치가 적을 경우 트리 기반 모델에서 과적합(overfitting)이 일어날 수 있다는 단점을 갖습니다.
댓글남기기