
[데이터 전처리] 데이터 스케일링 (Data Scaling)
이 글은 데이터 스케일링(Data Scaling)에 관한 기록입니다.
스케일링 개념
데이터 스케일링(Data Scaling)은 데이터의 값의 범위를 조정하는 것을 말합니다.
scikit-learn에서는 스케일링을 수행하는 다양한 스케일러를 제공합니다. 이때 모든 스케일러는 다음과 같은 메서드를 갖습니다.
SCALER.fit()- 데이터 변환을 학습
- train셋에 대해서만 적용
SCALER.transform()- 실제로 데이터 변환을 수행
- train셋과 test셋 모두에 대해서 적용
스케일링 종류
스케일링을 위해 scikit-learn에서는 MinMaxScaler, MaxAbsScaler, StandardScaler, RobustScaler을 제공합니다.
MinMaxScaler: 데이터가 0과 1 사이에 위치하도록 스케일링MaxAbsScaler: 데이터가 -1과 1 사이에 위치하도록 스케일링StandardScaler: 데이터의 평균 = 0, 분산 = 1이 되도록 스케일링RobustScaler: 데이터의 중앙값 = 0, IQE = 1이 되도록 스케일링
데이터의 분포 별로 각각의 스케일링 결과가 어떻게 다른지 살펴보면 다음과 같습니다.


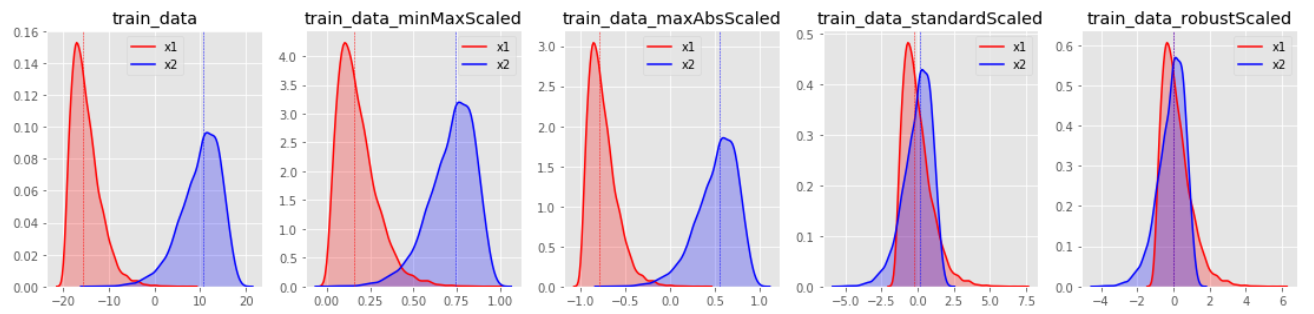

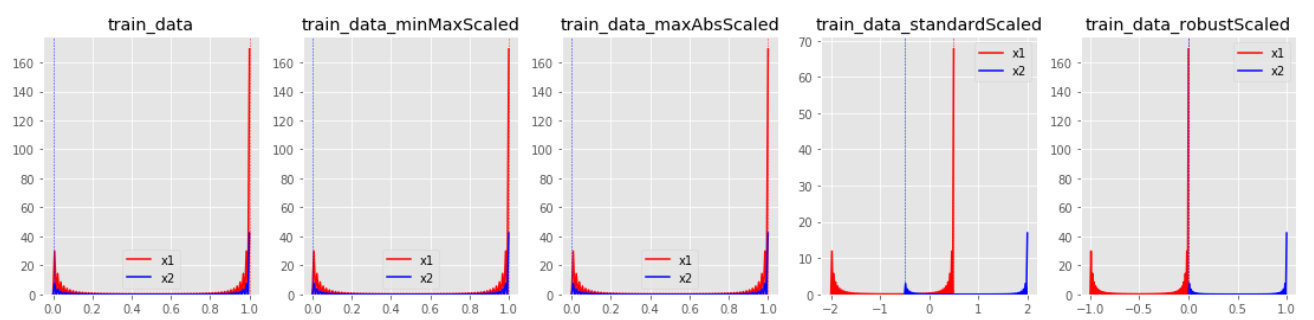
MinMaxScaler
- 데이터가 0과 1 사이에 위치하도록 스케일링 합니다. (default)
- 최소값 = 0, 최대값 = 1이 되도록 스케일링 합니다.
- (x - x의 최소값) / (x의 최대값 - x의 최소값)
- 데이터의 최소값과 최대값을 알 때 사용합니다.
- 이상치가 존재할 경우 스케일링 결과가 매우 좁은 범위로 압축될 수 있습니다.
from sklearn.preprocessing import MinMaxScaler
# minmax scaler 선언 및 학습
minmaxScaler = MinMaxScaler().fit(X_train)
# train셋 내 feature들에 대하여 minmax scaling 수행
X_train_minmax = minmaxScaler.transform(X_train)
# test셋 내 feature들에 대하여 minmax scaling 수행
X_test_minmax = minmaxScaler.transform(X_test)
MaxAbsScaler
- 데이터가 -1과 1 사이에 위치하도록 스케일링 합니다.
- 절대값의 최소값 = 0, 절대값의 최대값 = 1이 되도록 스케일링 합니다.
- 데이터의 값이 양수만 존재할 경우
MinMaxScaler와 유사하게 동작합니다. - 이상치가 큰 쪽에 존재할 경우 이에 민감할 수 있습니다.
from sklearn.preprocessing import MaxAbsScaler
# MaxAbsScaler 선언 및 학습
maxabsScaler = MaxAbsScaler().fit(X_train)
# train셋 내 feature들에 대하여 maxabs scaling 수행
X_train_maxabs = maxabsScaler.transform(X_train)
# test셋 내 feature들에 대하여 maxabs scaling 수행
X_test_maxabs = maxabsScaler.transform(X_test)
StandardScaler
- 데이터의 평균 = 0, 분산 = 1이 되도록, 즉 데이터가 표준 정규 분포(standard normal distribution)를 따르도록 스케일링 합니다.
- (x - x의 평균) / (x의 표준편차)
- 데이터의 최소값과 최대값을 모를 때 사용합니다.
- 평균(mean)과 분산(variance)을 사용합니다.
- 모든 feature들이 같은 스케일을 갖게 됩니다.
- 평균과 표준편차가 이상치로부터 영향을 많이 받는다는 점에서 이상치에 민감합니다.
from sklearn.preprocessing import StandardScaler
# standard scaler 선언 및 학습
standardScaler = StandardScaler().fit(X_train)
# train셋 내 feature들에 대하여 standard scaling 수행
X_train_standard = standardScaler.transform(X_train)
# test셋 내 feature들에 대하여 standard scaling 수행
X_test_standard = standardScaler.transform(X_test)
RobustScaler
- 데이터의 중앙값 = 0, IQE = 1이 되도록 스케일링 합니다.
- 중앙값(median)과 IQR(interquartile range)을 사용합니다.
RobustScaler를 사용할 경우StandardScaler에 비해 스케일링 결과가 더 넓은 범위로 분포합니다.
- 모든 feature들이 같은 스케일을 갖게 됩니다.
- 이상치의 영향을 최소화 합니다.
from sklearn.preprocessing import RobustScaler
# RobustScaler 선언 및 학습
robustScaler = RobustScaler().fit(X_train)
# train셋 내 feature들에 대하여 robust scaling 수행
X_train_robust = robustScaler.transform(X_train)
# test셋 내 feature들에 대하여 robust scaling 수행
X_test_robust = robustScaler.transform(X_test)
댓글남기기