
[NLP] LSTM (Long Short Term Memory networks)
이 글은 LSTM의 개념, 구조, 순전파, 역전파, 그리고 파이토치를 활용한 LSTM 구현에 관한 기록입니다.
1. LSTM의 개념
등장 배경
Long Short Term Memory networks(LSTMs)는 표준 RNN의 long-term dependencies, 즉 vanishing gradient 문제를 해결하기 위해 고안되었습니다.
표준 RNN vs. LSTM
모든 RNN은 신경망의 반복되는 모듈들의 체인의 형태를 가지고 있습니다. 표준 RNN과 LSTM은 이 반복되는 모듈이 가지고 있는 신경망 레이어의 개수에서 차이가 있습니다.
표준 RNN에서의 반복되는 모듈은 한개의 신경망 레이어를 가지고 있습니다. 예를 들어, 아래와 같이 표준 RNN에서의 반복되는 모듈은 하나의 하이퍼볼릭탄젠트 레이어를 가지고 있습니다.
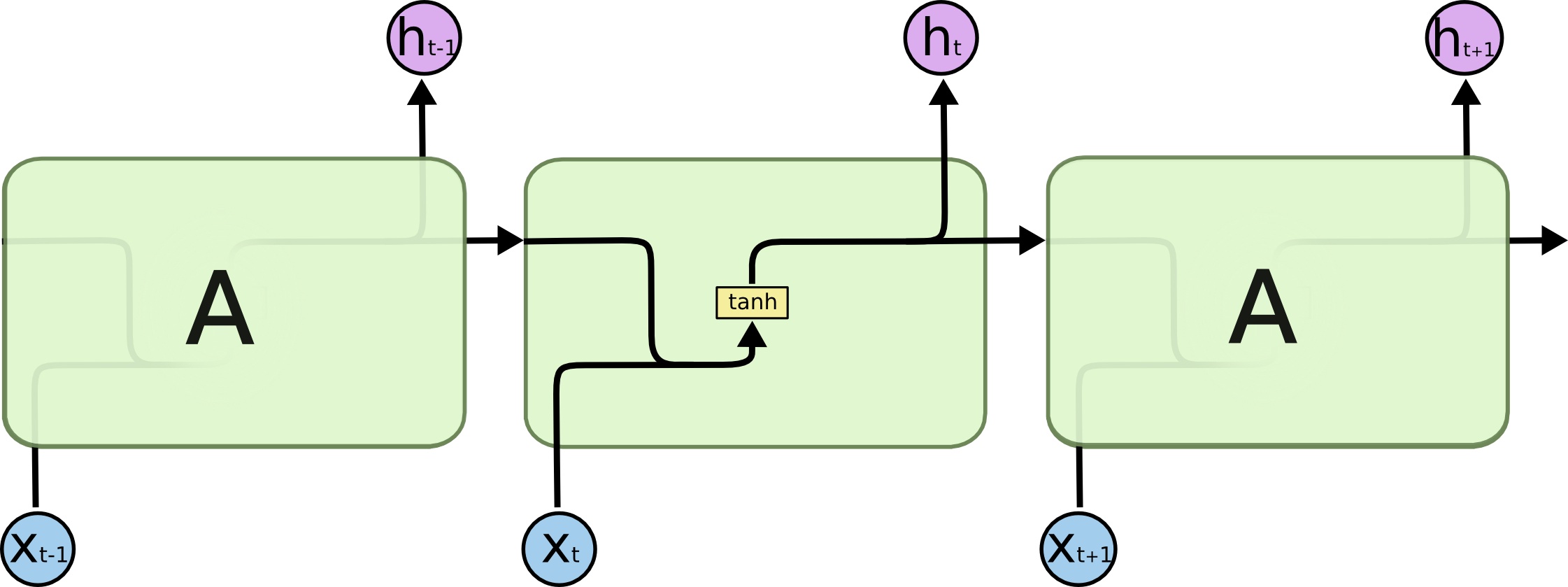
LSTM에서의 반복되는 모듈은 네개의 신경망 레이어를 가지고 있습니다. 그리고 이들은 특별한 방식으로 상호작용 합니다.
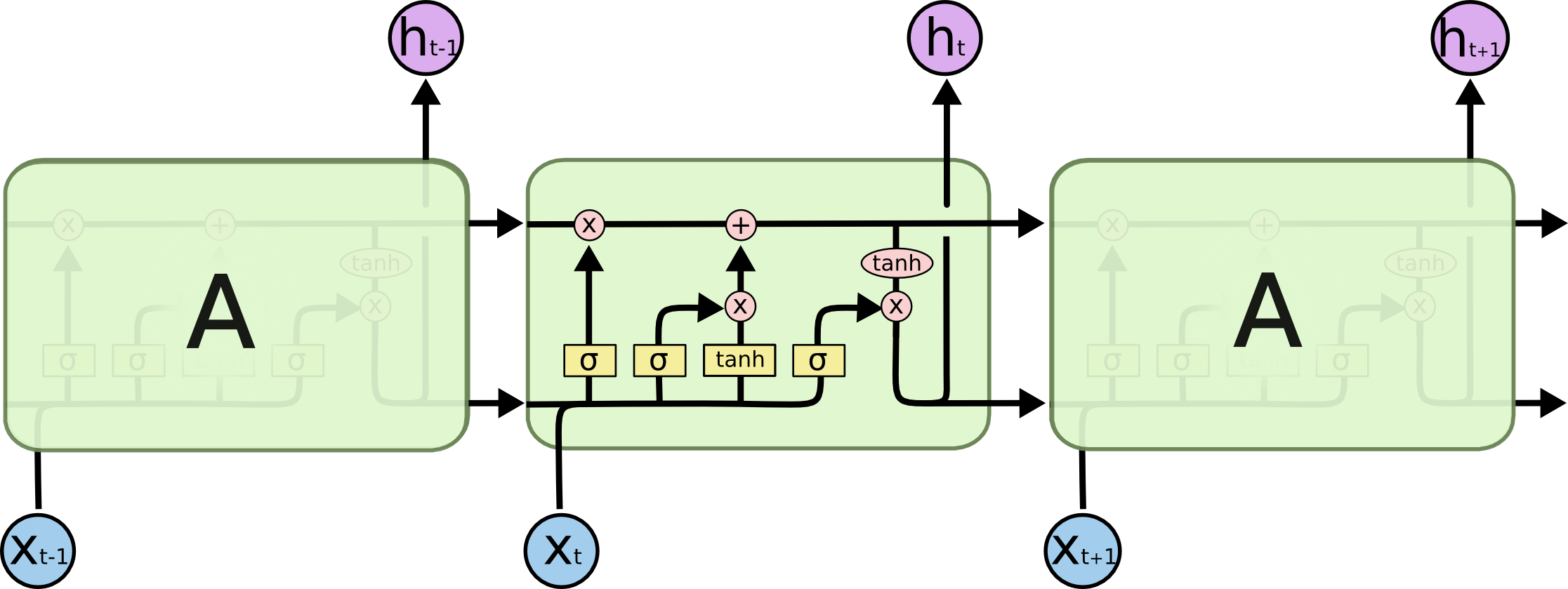
Notation 참고

- 노란색 박스 : 신경망 레이어
- 분홍색 원 : pointwise operation
- 선 : 한 노드의 출력에서 다른 노드의 입력까지 전체 벡터를 전달
- 선이 합쳐지는 것 : 내용이 결합
- 선이 갈라지는 것 : 내용이 복사되어 복사본이 다른 위치로 이동
Cell state
LSTM의 핵심은 cell state입니다.
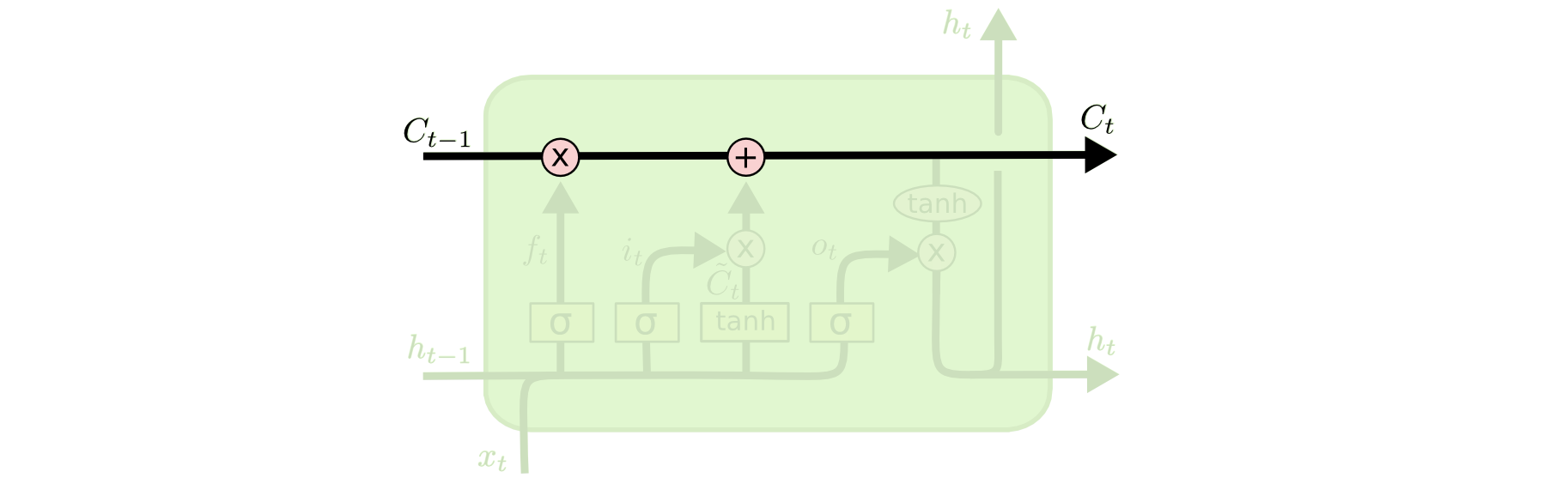
다이어그램 상단의 수평선이 cell state를 나타냅니다. cell state는 약간의 사소한 선형 상호작용만을 가지며 전체 체인을 따라 직진합니다. 이를 통해 정보가 변하지 않은 채 그대로 흘러갈 수 있습니다. LSTM은 cell state에 정보를 추가하거나 제거할 수 있는 능력을 가지고 있습니다. 이를 가능하게 하는 구조가 게이트입니다.
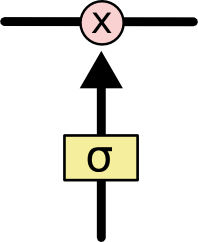
게이트는 선택적으로 정보를 통과시키는 방법입니다. 게이트는 시그모이드 신경망 레이어와 pointwise multiplication operation으로 구성되어 있습니다. 시그모이드 신경망 레이어는 0과 1 사이의 숫자를 출력하는데, 이는 각 구성요소가 얼마나 통과되어야 하는지를 나타냅니다. 0은 “아무것도 통과시키지 말 것”를 의미하고, 1은 “모든 것을 통과시킬 것”을 의미합니다. LSTM은 cell state를 보호하고 통제하기 위해 이러한 게이트를 3개 가지고 있습니다.
2. LSTM의 구조
Step 1. forget gate layer
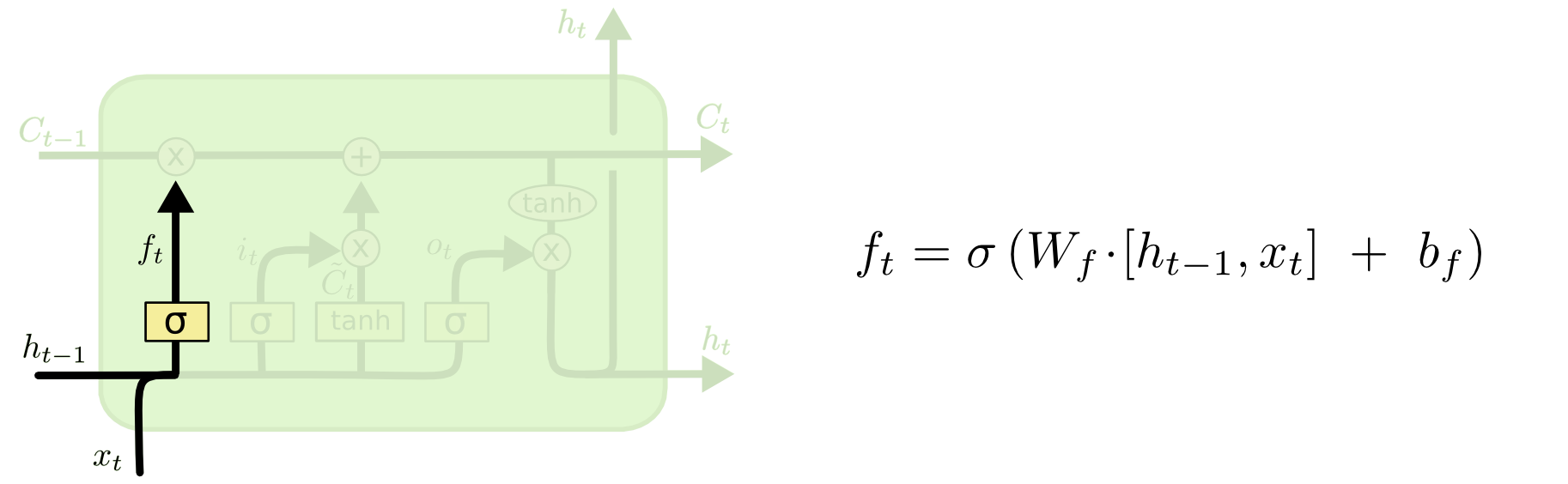
첫번째 단계는 cell state에 어떠한 정보를 제거할 것인지를 결정하는 단계입니다. 이러한 결정은 forget gate layer라고 불리는 시그모이드 레이어를 통해 이루어집니다. 시그모이드 레이어는 $h_{t-1}$와 $x_t$을 보고, cell state $C_{t-1}$의 각각의 번호에 대하여 0과 1 사이의 숫자를 출력합니다. 1은 “완전히 보관”을 나타내는 한편 0은 “완전히 제거”를 나타내는 의미를 담고 있습니다.
이전의 모든 단어를 바탕으로 다음 단어를 예측하려는 언어 모델을 예로 생각해봅시다. 여기에서, cell state는 정확한 대명사가 사용될 수 있도록 현재 주어의 성별을 포함하고자 합니다. 만약 새로운 주어를 보게 되면, 이전의 주어의 성별을 제거하고자 할 것입니다.
Step 2. Input gate
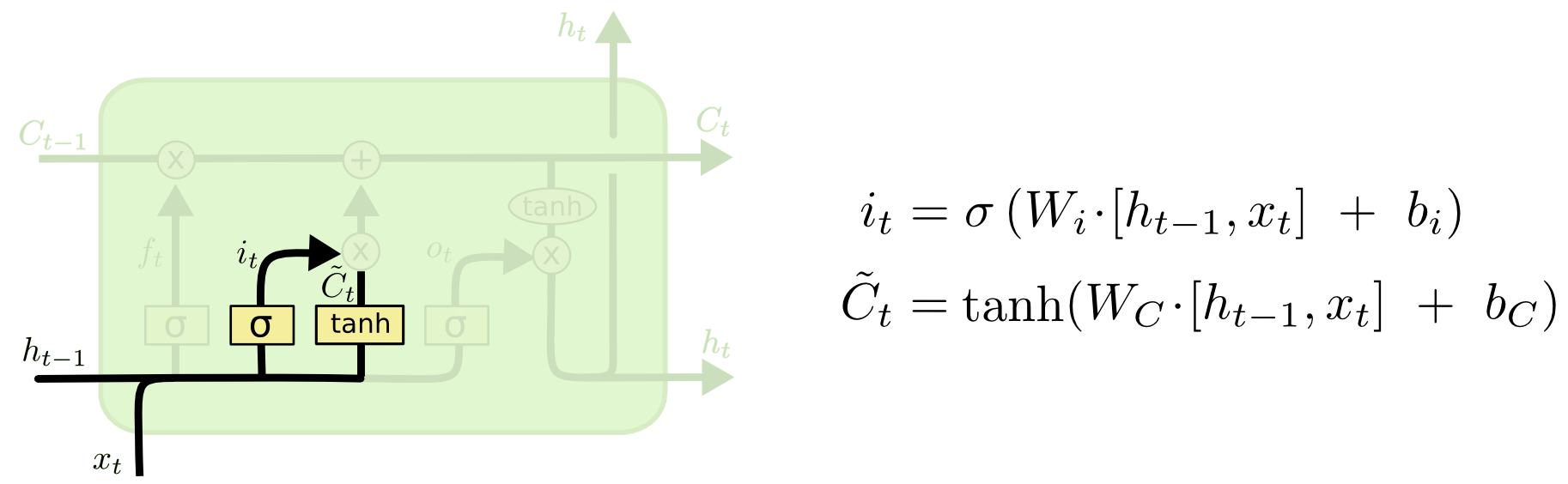
다음 단계는 cell state에 어떠한 새로운 정보를 추가할 것인지를 결정하는 단계입니다.
- 시그모이드 레이어가 어떠한 값을 업데이트 할 것인지를 결정 : input gate layer
- 하이퍼볼릭탄젠트 레이어가 cell state에 추가될 수도 있는 새로운 후보 값들의 벡터인 $\tilde{C_t}$를 생성 : update gate layer
- cell state를 업데이트 하기 위해 위 두가지를 결합
언어 모델의 예에서, 이전 단계에서 제거하기로 결정한 이전의 주어의 성별을 대체하기 위해 새로운 주어의 성별을 cell state에 추가하기를 원합니다.
Step 3. Cell state
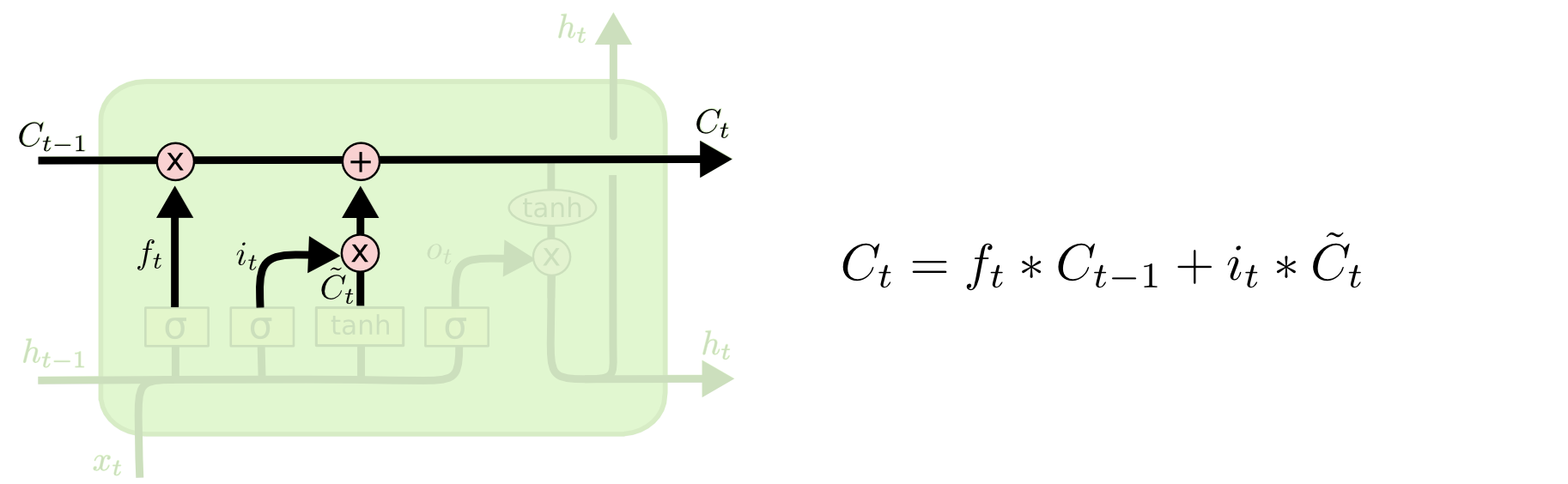
이제 이전의 cell state인 $C_{t-1}$를 새로운 cell state인 $C_t$로 업데이트 하는 단계입니다. Step 1과 Step 2에서는 무엇을 해야 할지 결정하였다면, Step 3에서는 이를 실제로 수행합니다.
먼저 이전의 cell state인 $C_{t-1}$에 $f_t$를 곱합니다. 이는 이전 단계에서 제거하기로 결정하였던 것들을 제거하기 위한 작업입니다. 그러고 나서 여기에 $i_t * \tilde{C_t}$를 더합니다. 이는 각 state의 값을 업데이트 하기로 결정한 정도에 따라 스케일링 하는 작업입니다. 이들이 새로운 후보 값들이 됩니다.
언어 모델의 예에서, 이전 단계에서 결정한 바를 바탕으로, 이 단계에서는 실제로 이전의 주어의 성별에 대한 정보를 제거하고 새로운 정보를 추가합니다.
Step 4. Output gate

마지막 단계는 무엇을 출력할 것인지를 결정하는 단계입니다. 이때의 출력물은 cell state를 기반으로 하되 이를 필터링 한 버전이 됩니다. 먼저 cell state의 어떤 부분을 출력할 것인지를 결정하는 시그모이드 레이어를 실행하여 $o_t$를 얻습니다. 그리고 cell state $C_t$를 하이퍼볼릭탄젠트 함수에 통과시킵니다. 그러고 나서 출력하기로 결정한 부분만 출력할 수 있도록 이들을 즉 $o_t$와 $\tanh \left( C_t \right)$를 곱합니다.
언어 모델의 예에서, 방금 주어를 봤기 때문에 다음에 다가올 경우에 대비하여 동사와 관련된 정보를 출력하고 싶을 것입니다. 예를 들어, 다음에 어떤 형태로 동사가 결합되어야 하는지 알 수 있도록 주어가 단수인지 복수인지를 출력할 수 있습니다.
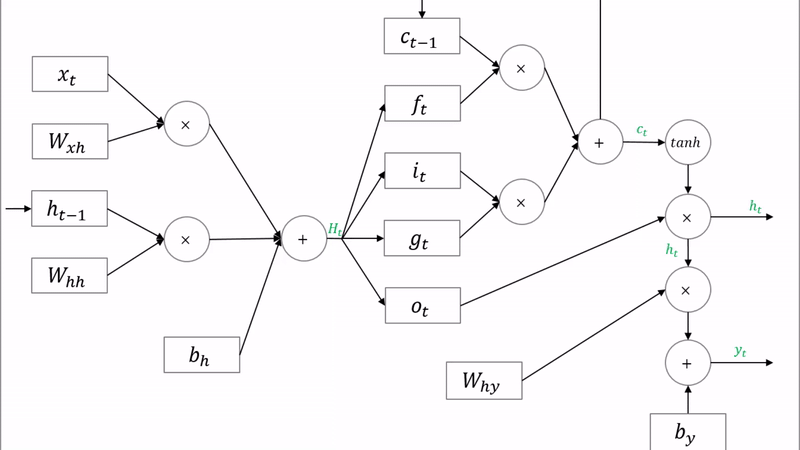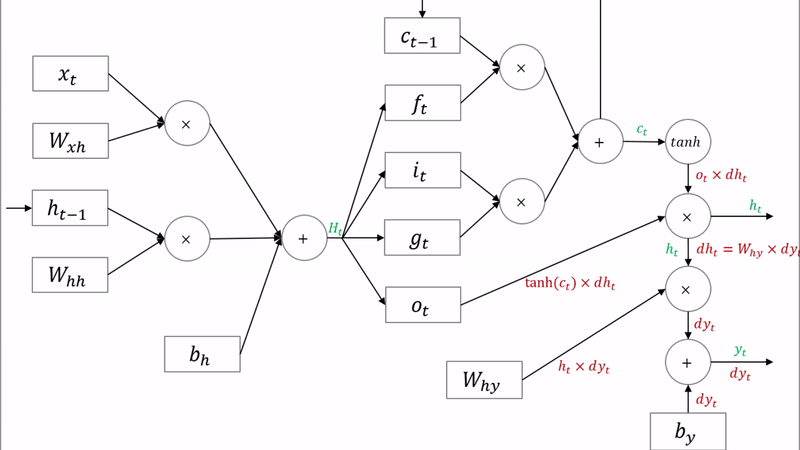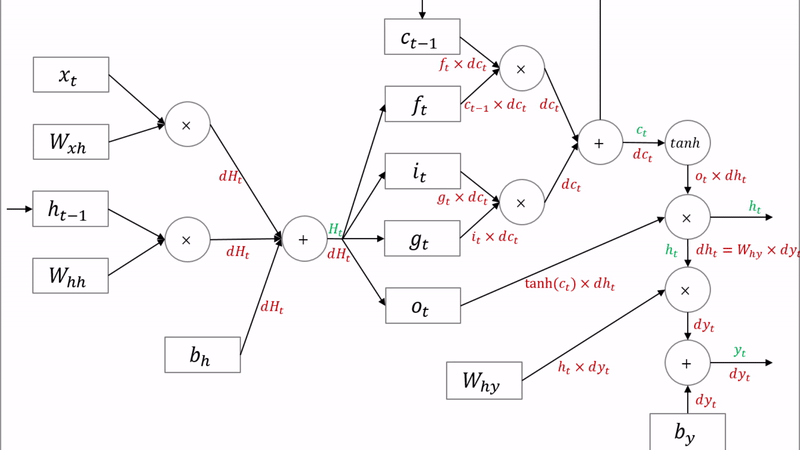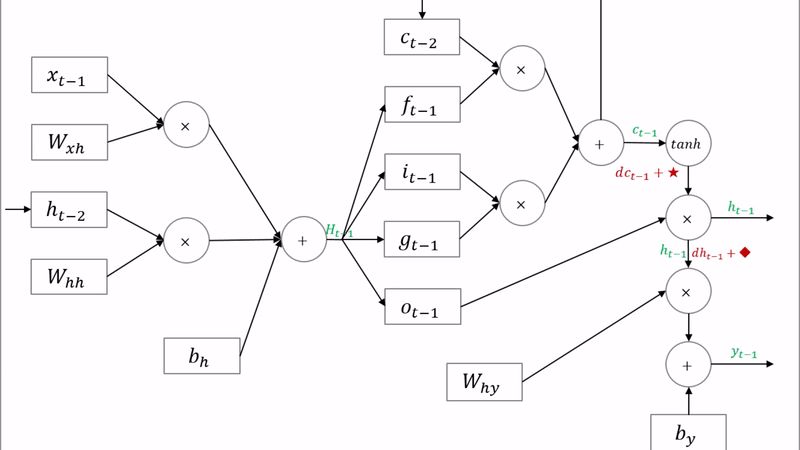
3. LSTM의 순전파 (Forward pass)

여기서 주목해야 할 점은 $H_t$입니다. 이 행렬 $H_t$를 행을 기준으로 4등분 하여 $f$, $i$, $g$, $o$ 각각에 해당하는 활성함수를 적용함으로써 $f_t$, $i_t$, $g_t$, $o_t$를 계산합니다. $f$, $i$, $o$의 활성함수는 시그모이드이고, $g$의 활성함수는 하이퍼볼릭탄젠트입니다. 이를 그림으로 나타내면 다음과 같습니다.
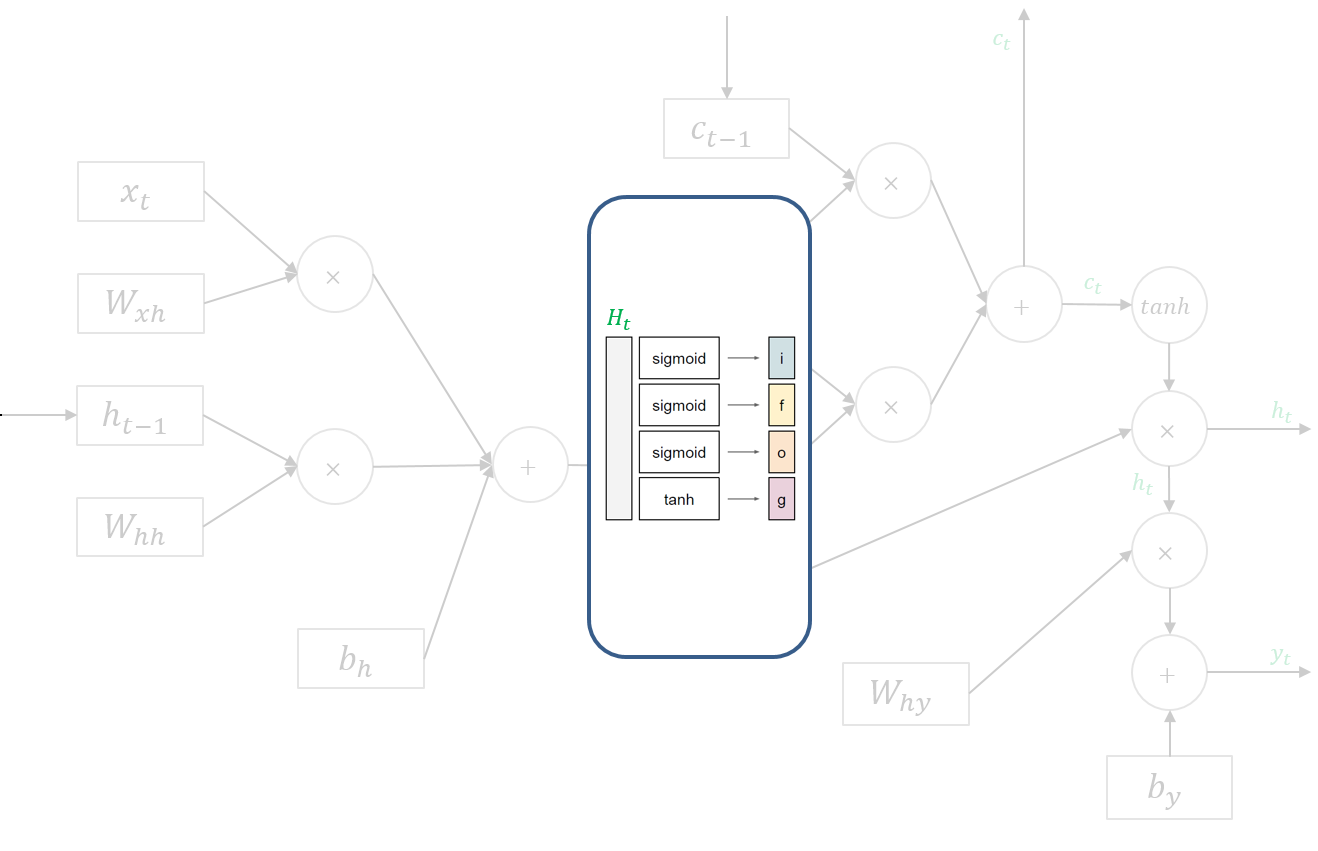
4. LSTM의 역전파 (Backward pass)
LSTM의 backward pass의 전체적인 과정은 다음과 같습니다.
우선 $df_t$, $di_t$, $dg_t$, $do_t$를 구하기 전까지의 backward pass는 아래와 같습니다. 표준 RNN과 유사한 것을 볼 수 있습니다.
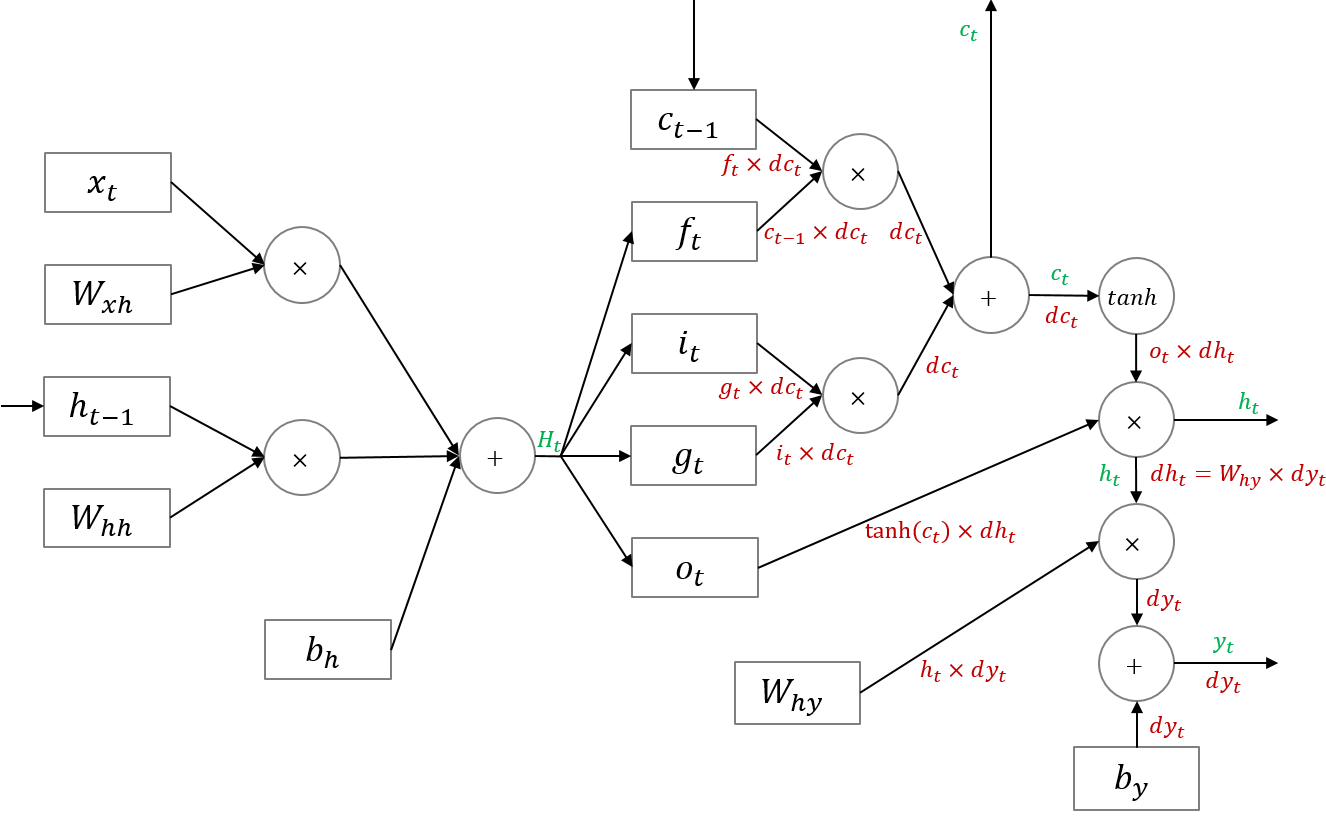
다음으로 $df_t$, $di_t$, $dg_t$, $do_t$를 구하는 과정에 대해 살펴보겠습니다. $f$, $i$, $o$의 활성함수는 시그모이드이고 $g$의 활성함수는 하이퍼볼릭탄젠트입니다. 아래와 같이 각각의 활성함수에 대한 로컬 그래디언트를 구해 흘러들어온 그래디언트를 곱해주면 $df_t$, $di_t$, $dg_t$, $do_t$를 구할 수 있습니다.
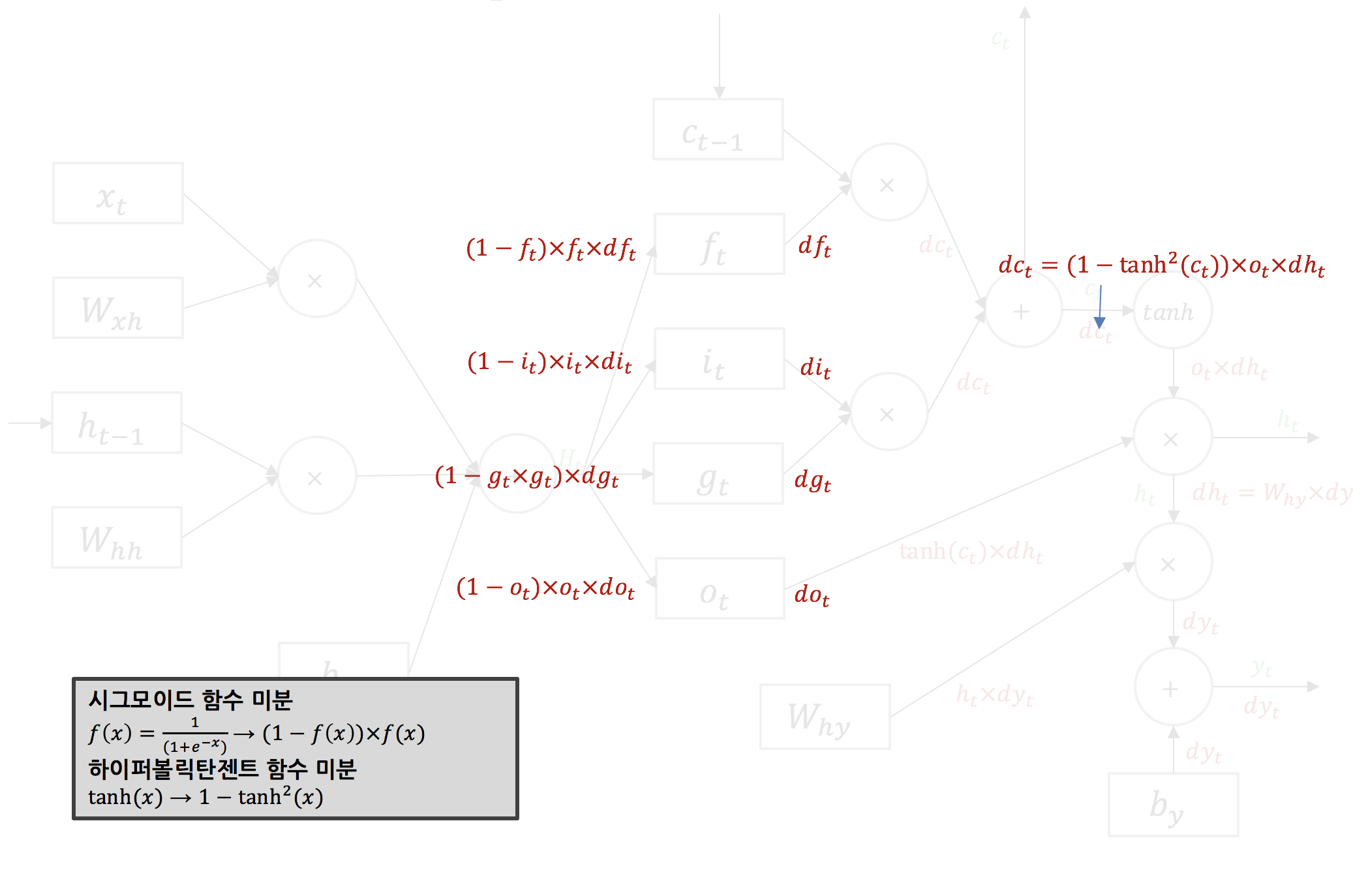
forward pass에서 $H_t$를 4등분 하여 $f_t$, $i_t$, $g_t$, $o_t$를 구했던 것처럼, backward pass에서는 이렇게 구한 $df_t$, $di_t$, $dg_t$, $do_t$를 다시 합쳐 $dH_t$를 만듭니다.
이렇게 구한 $dH_t$는 아래와 같이 표준 RNN과 같은 방식으로 backward pass가 이루어지는 구조입니다.
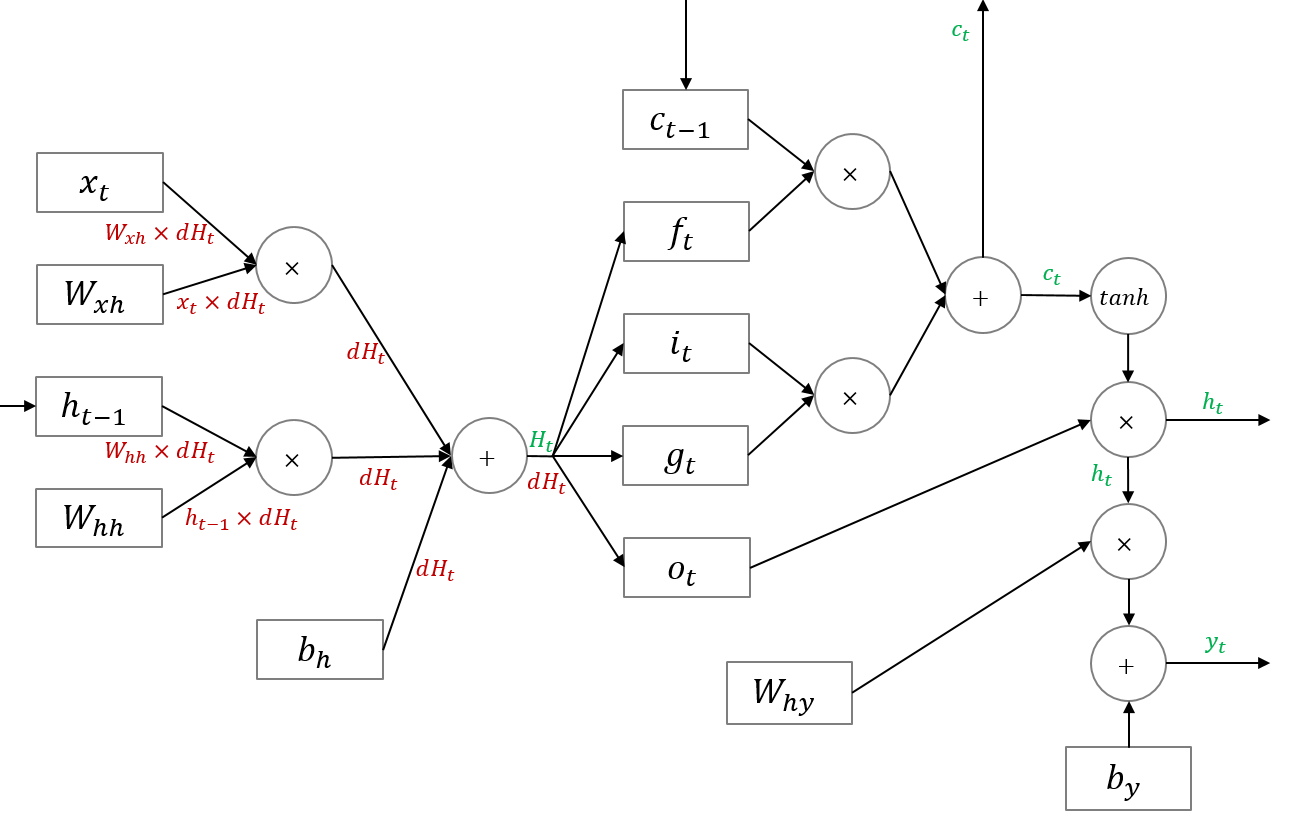
LSTM은 cell state와 hidden state가 재귀적으로 구해지는 네트워크입니다. 따라서 cell state의 그래디언트와 hidden state의 그래디언트는 직전 시점의 그래디언트 값에 영향을 받습니다. 이는 표준 RNN과 마찬가지입니다. 이를 backward pass 시 반영해야 합니다.
5. LSTM Code
Settings
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
sentences = ["i like dog", "i love coffee", "i hate milk", "you like cat", "you love milk", "you hate coffee"]
dtype = torch.float
Text Processing
word_list = list(set(" ".join(sentences).split()))
word_dict = {w: i for i, w in enumerate(word_list)}
number_dict = {i: w for i, w in enumerate(word_list)}
n_class = len(word_dict)
TextLSTM Parameter
batch_size = len(sentences)
n_step = 2 # 학습하려고 하는 문장의 길이 - 1
n_hidden = 5 # 은닉층 사이즈
def make_batch(sentences):
input_batch = []
target_batch = []
for sen in sentences:
word = sen.split()
input = [word_dict[n] for n in word[:-1]]
target = word_dict[word[-1]]
input_batch.append(np.eye(n_class)[input]) # One-Hot Encoding
target_batch.append(target)
return input_batch, target_batch
input_batch, target_batch = make_batch(sentences)
input_batch = torch.tensor(input_batch, dtype=torch.float32, requires_grad=True)
target_batch = torch.tensor(target_batch, dtype=torch.int64)
TextLSTM
class TextLSTM(nn.Module):
def __init__(self):
super(TextLSTM, self).__init__()
self.lstm = nn.LSTM(input_size=n_class, hidden_size=n_hidden, dropout=0.3)
self.W = nn.Parameter(torch.randn([n_hidden, n_class]).type(dtype))
self.b = nn.Parameter(torch.randn([n_class]).type(dtype))
self.Softmax = nn.Softmax(dim=1)
def forward(self, hidden_and_cell, X):
X = X.transpose(0, 1)
outputs, hidden = self.lstm(X, hidden_and_cell)
outputs = outputs[-1] # 최종 예측 Hidden Layer
model = torch.mm(outputs, self.W) + self.b # 최종 예측 최종 출력 층
return model
Traning
model = TextLSTM()
# Loss & Optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
# Training
for epoch in range(500):
hidden = torch.zeros(1, batch_size, n_hidden, requires_grad=True)
cell = torch.zeros(1, batch_size, n_hidden, requires_grad=True)
output = model((hidden, cell), input_batch)
loss = criterion(output, target_batch)
if (epoch + 1) % 100 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
input = [sen.split()[:2] for sen in sentences]
hidden = torch.zeros(1, batch_size, n_hidden, requires_grad=True)
cell = torch.zeros(1, batch_size, n_hidden, requires_grad=True)
predict = model((hidden, cell), input_batch).data.max(1, keepdim=True)[1]
print([sen.split()[:2] for sen in sentences], '->', [number_dict[n.item()] for n in predict.squeeze()])
Epoch: 0100 cost = 0.346767
Epoch: 0200 cost = 0.032417
Epoch: 0300 cost = 0.014241
Epoch: 0400 cost = 0.008376
Epoch: 0500 cost = 0.005602
[['i', 'like'], ['i', 'love'], ['i', 'hate'], ['you', 'like'], ['you', 'love'], ['you', 'hate']] -> ['dog', 'coffee', 'milk', 'cat', 'milk', 'coffee']
댓글남기기