
[CV] CNN (Convolution Neural Networks) ; 합성곱 신경망
이 글은 CNN의 개념 및 구조에 관한 기록입니다.
CNN 개념
CNN은 이미지를 다루는 데에 활용되는 Deep Neural Network입니다. CNN의 목표는 정보의 손실 없이 이미지를 줄이는 것입니다. 이를 위해 CNN에서는 Convolution layer와 ReLU layer, Pooling layer를 통해 feature를 추출/학습하고, Fully-Connected layer를 통해 이미지를 분류합니다. 이를 그림으로 나타내면 다음과 같습니다.
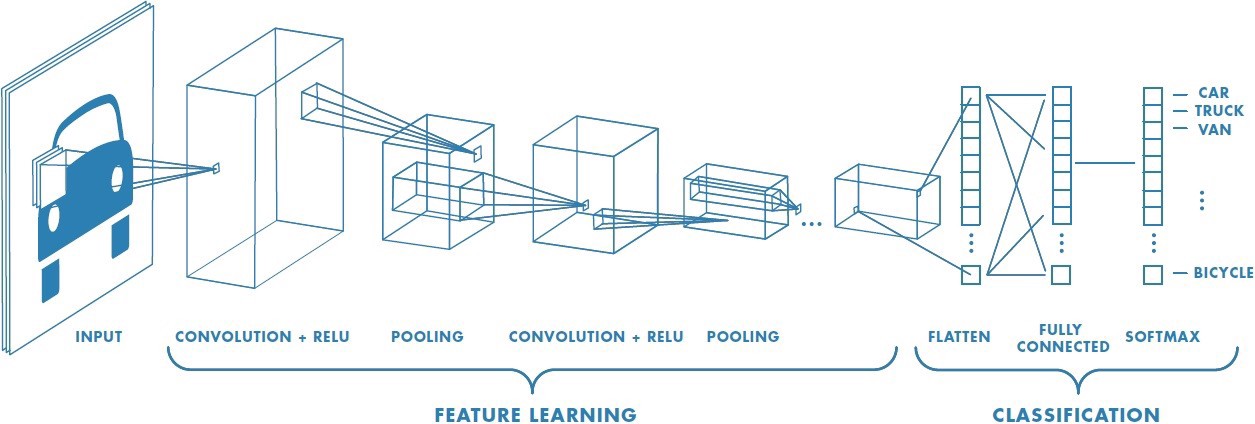
즉 CNN은 크게 Convolution layer, Pooling layer, Full-Connected layer 세가지 종류의 layer로 구성됩니다.
((CONV + RELU) * m => POOL) * n => (FC + RELU) * k
m=1~5, n=큰 수, k=0~2
CNN의 구조
CNN의 기본적인 구조는 다음과 같습니다.

- INPUT :
120 x 160 x 1 - Convolution 1 : Convolution Layer :
5 x 5 x 1filter12개 사용- output size =
116 x 156 x 12
- output size =
- Maxpooling 1 : Pooling Layer :
2 x 2max pooling 사용- output size =
58 x 78 x 12
- output size =
- Convolution 2 : Convolution Layer :
5 x 5 x 1filter16개 사용- output size =
54 x 74 x 16
- output size =
- Maxpooling 2 : Pooling Layer :
2 x 2max pooling 사용- output size =
27 x 37 x 16
- output size =
- Convolution 3 : Convolution Layer :
4 x 4 x 1filter20개 사용- output size =
24 x 34 x 20
- output size =
- Maxpooling 3 : Pooling Layer :
2 x 2max pooling 사용- output size =
12 x 17 x 20
- output size =
- FC 1 : Fully-Connected Layer
- output size =
512 x 1
- output size =
- FC 2 : Fully-Connected Layer
- output size =
128 x 1
- output size =
- FC 3 : Fully-Connected Layer
- output size =
4 x 1
- output size =
- OUTPUT :
4 x 1
1. Convolution Layer
Convolution ; 합성곱
Convolution은 이미지로부터 feature를 추출하기 위해 사용하는 연산입니다. 이를 그림으로 나타내면 다음과 같습니다.
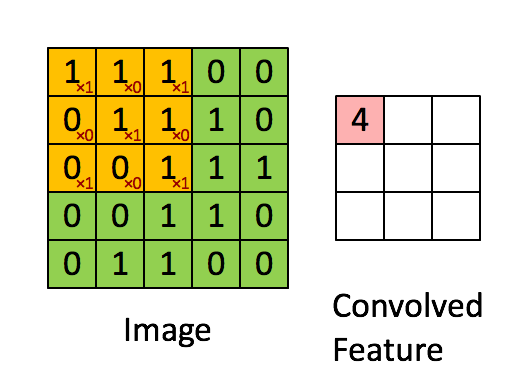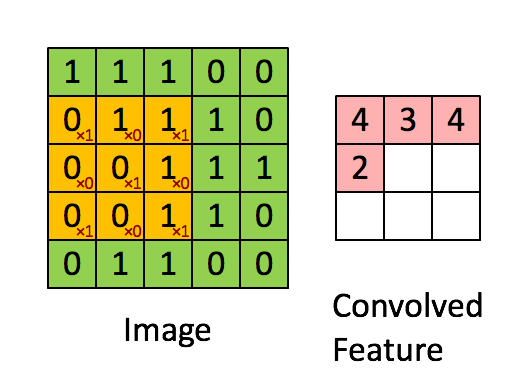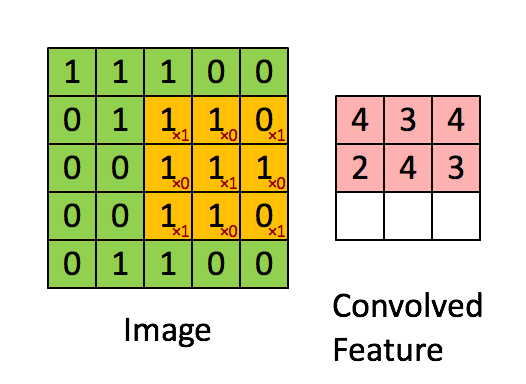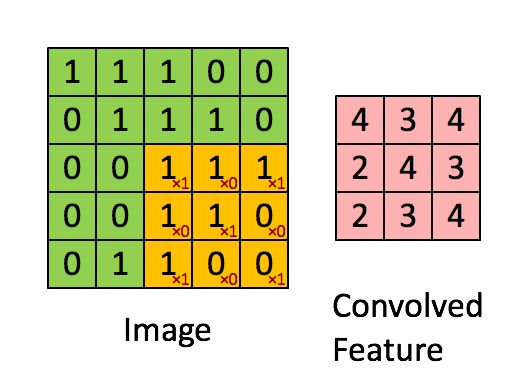
- 초록색 부분 : 입력 이미지
5 x 5 x 1 - 노란색 부분 : filter = kernel
3 x 3 x 1 - 빨간색 숫자 : filter 내 값 : 가중치(weight)
- 빨간색 부분 : feature map
위 그림에서는 5 x 5 입력 이미지에 대하여 3 x 3 filter를 한칸씩 움직이며(stride = 1) 매번 이미지의 일부와 filter 간 matrix operation을 수행하여 최종적으로 3 x 3 feature map을 추출합니다. 이때 matrix operation, 즉 각 요소끼리 곱하고 이를 모두 더하는 연산을 convolution이라고 합니다.
2차원 데이터에서의 Convolution
흑백 이미지는 명암만을 표현하여 1개의 채널을 갖는 2차원 데이터입니다.
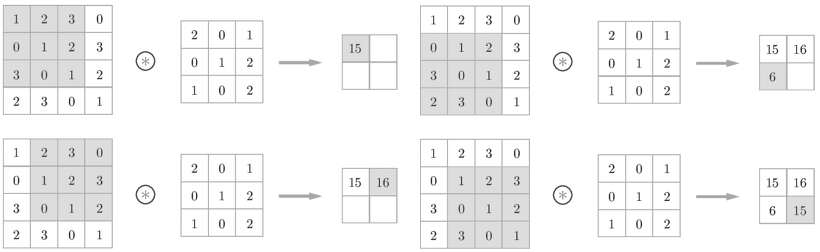
예를 들어, 4 x 4 x 1 입력 이미지에 대하여 3 x 3 x 1 filter를 1개 사용하여 convolution을 수행한다고 생각해봅시다. 입력 이미지와 filter 간 matrix operation을 수행하여 2 x 2 x 1 feature map, 즉 1개의 채널을 갖는 feature map을 반환합니다. 이를 그림으로 나타내면 다음과 같습니다.
3차원 데이터서의 Convolution
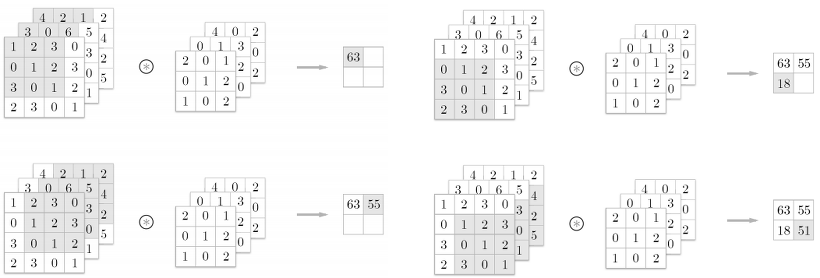
컬러 이미지는 Red, Green, Blue 총 3개의 채널을 갖는 3차원 데이터입니다. 3차원 데이터에 대하여 convolution을 수행할 때에는 입력 데이터의 채널 수와 filter의 채널 수가 같아야 합니다.
예를 들어, 4 x 4 x 3 입력 이미지에 대하여 3 x 3 x 3 filter를 1개 사용하여 convolution을 수행한다고 가정해봅시다. 각각의 채널 별로 입력 이미지와 filter 간 matirx operation을 수행한 뒤 이들을 모두 더하여 2 x 2 x 1 feature map, 즉 1개의 채널을 갖는 feature map을 반환합니다. 이를 그림으로 나타내면 다음과 같습니다.
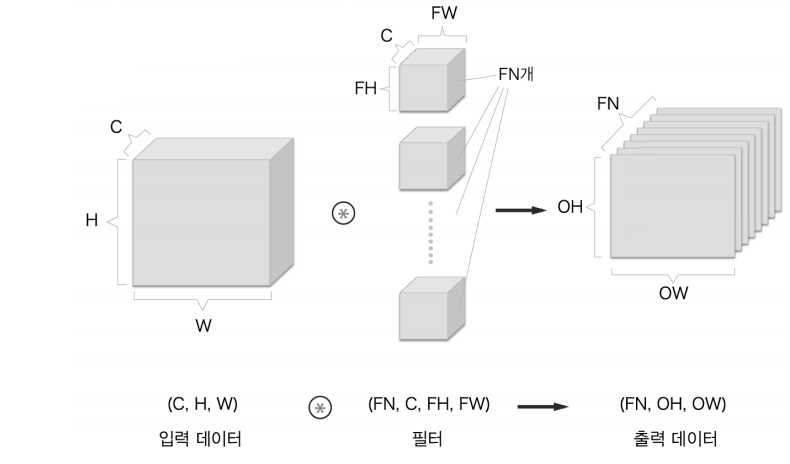
일반적으로 CNN에서는 IW x IH x IC 입력 이미지에 대하여 FW x FH x FC filter를 FN개 사용하여 convolution을 수행함으로써 OW x OH x FN feature map을 반환하도록 합니다.
Filter = Kernel
Filter(=Kernel)은 convolution을 수행할 때 사용되는 정사각행렬입니다. CNN에서 filter는 학습 대상 파라미터입니다. 즉 filter 내 숫자들은 가중치(weight)로, backpropagation을 통해 학습됩니다.
- filter의 크기 (filter size = kernel size)
- 일반적으로 이미지의 크기가 클수록 더 큰 filter를 사용합니다.
- 보통 큰 size의 filter를 한 개 사용하는 것보다 작은 size의 filter를 여러 개 사용하는 것이 성능이 더 좋다고 더 좋은 성능을 낸다고 알려져 있습니다.
- filter의 개수
- 하나의 입력에 여러 개의 filter를 사용하면 다양한 feature들을 추출할 수 있습니다.
- 일반적으로 각 레이어 별 연산 시간 및 양이 일정할 수 있도록 filter의 개수를 결정합니다.
- 예를 들어, 이전 레이어에서 픽셀 수가 1/4로 줄어들었다면, 다음 레이어에서는 filter 수를 4배 늘리는 방식입니다.
- 입력 이미지로부터 가까운 레이어에서는 filter를 적게 사용하고, 입력 이미지로부터 먼 레이어에서는 filter를 많이 사용하는 경향이 있습니다.
- stride : stride는 filter를 몇 칸씩 움직이면서 convolution을 수행할 것인지를 의미합니다.
- 일반적으로
stride = 1로 설정합니다. - stride 값이 커지면 local feature의 특성을 고려하지 못한 global feature를 추출하게 될 가능성이 높습니다.
- 일반적으로
Padding
Padding은 입력 이미지의 가장자리에 특정 값으로 설정된 픽셀들을 추가하는 것을 의미합니다. 일반적으로 0으로 설정된 픽셀들을 추가하는 zero-padding을 많이 사용합니다.

padding의 효과는 다음과 같습니다.
- convolution 이후 feature map의 크기가 입력 이미지의 크기에 비해 작아지는 것을 방지할 수 있습니다.
- padding을 적용함으로써 이미지의 가장자리에 있는 정보의 손실을 줄일 수 있습니다.
예를 들어, 4 x 4 x 1 이미지가 있다고 가정해봅시다.
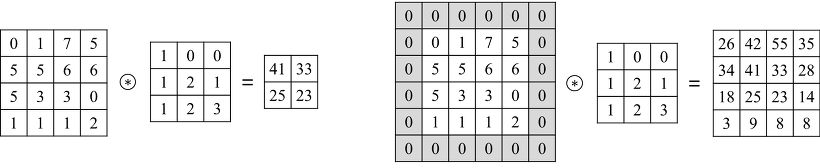
왼쪽 그림처럼 입력 이미지에 padding을 적용하지 않고 3 x 3 x 1 filter를 stride = 1로 하여 convolution을 수행하면 2 x 2 x 1 feature map을 얻게 됩니다. 한편 오른쪽 그림처럼 이 입력 이미지에 zero-padding = 1을 적용하여 3 x 3 x 1 filter를 stride = 1로 하여 convolution을 수행하면 입력 이미지와 크기가 동일한 4 x 4 x 1 feature map을 얻을 수 있습니다.
Feature Map & Activation Map
Feature Map은 convolution을 수행하여 반환되는 output을 말합니다. 이에 따라 feature map의 size는 filter size, padding size, stride에 의해 결정됩니다. 공식은 다음과 같습니다.
$OW = \frac{IW - FW + 2P}{S} + 1, \quad OH = \frac{IW - FH + 2P}{S} + 1$
- $OW$, $OH$ : output width, output height => output size
- $IW$, $IH$ : input width, input height => input size
- $FW$, $FH$ : filter width, filter height => filter size
- $P$ : padding size
- $S$ : stride
Activation Map은 feature map에 ReLU와 같은 활성화 함수(activation function)을 적용하여 반환되는 output을 가리킵니다. 따라서 convolution layer의 최종 output이 activation map이라고 할 수 있습니다.
2. Pooling layer
Pooling
Pooling은 sub sampling입니다. 즉 데이터의 크기를 줄이는 것입니다. 아래의 그림은 5 x 5 데이터에 3 x 3 pooling을 적용하는 것을 보여줍니다.
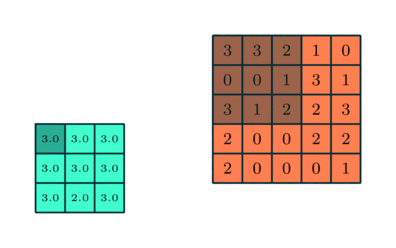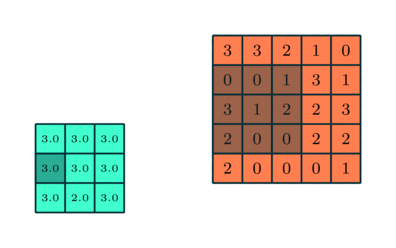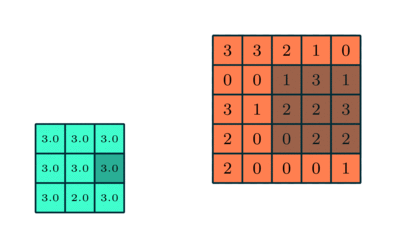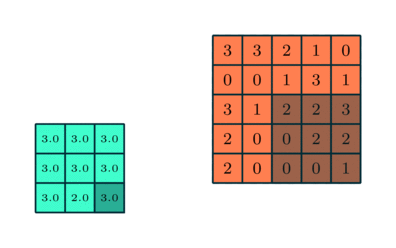
pooling의 효과는 다음과 같습니다.
- overfitting을 방지합니다.
- 데이터의 크기를 줄여 파라미터 수가 줄어듦에 따라 computation 또한 줄어듭니다.
pooling의 종류는 다음과 같습니다.
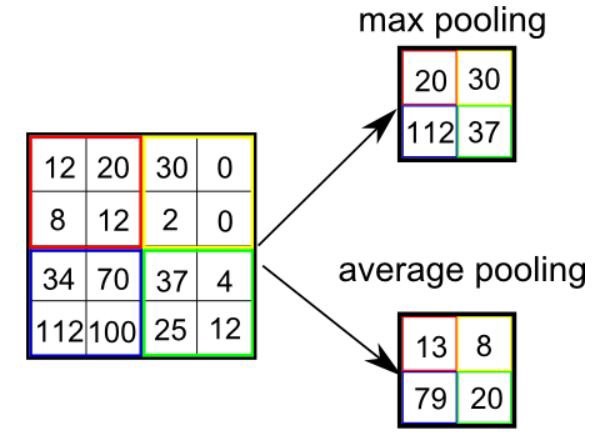
- Max Pooling : 영역 내 최대값 반환
- Average Pooling : 영역 내 평균값 반환
- Min Pooling : 영역 내 최소값 반환
- Stochastic Pooling
- Cross Channel Pooling
- …
Pooling Layer in CNN
pooling layer는 convolution layer의 출력을 입력으로 받아 크기를 줄이거나 특정 데이터를 강조하기 위해 사용됩니다. 일반적으로 pooling의 크기와 stride를 동일하게 설정하여 모든 픽셀이 한번씩 처리될 수 있도록 합니다. 또 CNN에서는 주로 max pooling을 사용하는데, 이를 통해 차원을 축소할 수 있고 지배적인 feature를 추출할 수 있습니다.
pooling layer의 특징은 다음과 같습니다.
- 학습 대상 파라미터가 없습니다.
- pooling layer의 입력과 출력의 채널 수는 동일합니다. 즉 pooling이 채널 수에 영향을 미치지 않아 채널 수가 유지됩니다. (independent)
- pooling layer의 입력인 feature map에 변화가 있더라도 pooling의 출력에는 변화가 거의 없습니다. (robustness)
pooling layer의 output size는 다음과 같습니다.
$OW = \frac{IW}{P}, \quad OH = \frac{IH}{P}$
- $OW$, $OH$ : output width, output height => output size
- $IW$, $OH$ : input width, input height => input size
- $P$ : padding size
3. Fully-Connected layer

Fully-Connected layer에서는 데이터를 flatten하여 1차원 배열로 변환하고, FFNN을 거치고, Softmax 함수를 사용함으로써 최종적으로 이미지를 분류할 수 있도록 합니다.
CNN 계열 모델
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
참고자료
Backpropagation applied to handwritten zip code recognition
A Comprehensive Guide to Convolutional Neural Networks — the ELI5 way
밑바닥부터 시작하는 딥러닝
TAEWAN.KIM님의 블로그
댓글남기기